Sejamos honestos, programar com um LLM é muitas vezes comparável a trabalhar com um desenvolvedor júnior, mas com uma inconsistência absurda. Ele pode gerar um código de base muito bom, e logo depois ‘alucinar’ uma dependência que nem existe. Queremos um parceiro sênior, mas a realidade é que vira um jogo de tentativa e erro. Essa diferença só é resolvida quando você aplica as boas práticas de prompt engineering para pedir algo a um LLM.
Primeiro, Pare de Tratar o LLM como uma bola de cristal
Antes mesmo de escrever o prompt, você precisa definir o problema com precisão. LLMs só conseguem trabalhar bem com o que você entrega. Se o input vem confuso, genérico ou grande demais, o output vai seguir a mesma linha: resposta ampla, pouco útil e, muitas vezes, incorreta.
Defina um Objetivo Claro e Específico
Isso parece óbvio, mas é o ponto onde mais falhamos. Pedimos coisas demais de uma só vez.
- Ruim: “Escreva um microsserviço de autenticação de usuários.”
- Bom: “Escreva uma função em Go usando o framework Gin. Ela deve ser um endpoint POST em
/login. Precisa analisar um corpo JSON com os campos ‘email’ e ‘password’, fazer o hash da senha fornecida com bcrypt e compará-la com o hash armazenado buscado de um banco PostgreSQL.”
O segundo prompt define a linguagem, o framework, o endpoint, o método, o formato dos dados e a lógica central. Há bem menos espaço para o LLM sair dos trilhos.
Ajuste o Tamanho da Tarefa
LLMs são ótimos para tarefas pequenas e bem definidas. O problema aparece quando você tenta fazer com que eles gerenciem planos longos, cheios de etapas e dependências. Não peça para “construir o carro inteiro” de uma vez. Peça para montar o carburador, depois as velas, depois o bloco do motor, uma peça por vez, do jeito que eles funcionam melhor.
Divida o trabalho. Por exemplo, em vez de “Refatore essa classe inteira”, tente uma sequência:
- “Identifique métodos nesta classe Java que ultrapassem 30 linhas ou tenham complexidade ciclomática maior que 5.”
- “Certo, para o método
calculateUserPermissionsque você encontrou, sugira uma estratégia de refatoração para quebrá-lo em métodos auxiliares privados menores.” - “Agora escreva o código para o novo método auxiliar
getUserRolesque você sugeriu.”
Como Construir um Prompt que Funciona na Prática
Um bom prompt não é só uma pergunta, é uma especificação. Descobri que uma estrutura em camadas funciona melhor, dando ao modelo tudo o que ele precisa para ter sucesso. Pense nisso como um ticket bem escrito no Jira.
Boas Práticas de Prompt Engineering para Estrutura
- Persona e Contexto: Diga ao LLM quem ele é e forneça as informações de fundo.
- A Tarefa Específica: Declare claramente o que você quer que ele faça.
- Restrições e Regras: Defina limites e pontos inegociáveis.
- Exemplos (Few-Shot): Mostre o que significa “bom”.
Use delimitadores como ou tags XML para manter essas seções organizadas. O modelo interpreta bem estruturas.
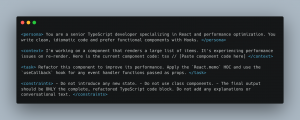
Essa estrutura reduz muito a margem de erro. Você define a persona, passa o trecho relevante, explica exatamente quais técnicas de refatoração usar e ainda controla o formato da saída. A diferença de confiabilidade quando você compara com um simples “deixa esse componente mais rápido” é absurda.
Fazendo o LLM “Pensar” Antes de Escrever
Um dos maiores avanços em prompting é obrigar o modelo a pensar antes de responder. Isso é o famoso Chain-of-Thought (CoT) e, hoje, é uma das melhores defesas contra respostas absurdas ditas.
A lógica é simples: você pede para o modelo explicar o raciocínio passo a passo antes de chegar na conclusão. É assim que um engenheiro sênior trabalha: ele não começa escrevendo código direto. Primeiro descreve o plano, depois parte para a implementação.
Aplicando Chain-of-Thought em Código
Imagine que você está depurando uma query SQL complicada. Em vez de pedir uma correção direta, guie o raciocínio.
Um prompt ruim:
"Corrija essa query SQL. Ela está lenta."
Um prompt bom, com CoT:
"Preciso que você analise e otimize a seguinte query SQL. Siga estes passos na sua resposta:
-
Analisar a consulta: Primeiro, explique em linguagem simples o que a query está tentando fazer. Identifique as tabelas, os joins e as condições de filtro.
-
Identificar possíveis gargalos: Com base na análise, liste as causas mais prováveis de baixo desempenho. Considere coisas como ausência de índices, varreduras completas de tabela ou tipos de join ineficientes.
-
Propor uma consulta otimizada: Por fim, escreva a versão reescrita e otimizada da query SQL.
Aqui está a query original:
sql
— [Cole aqui a query SQL]
”
Isso força o LLM a deixar explícito o “como” ele chegou lá. E isso muda tudo. Agora você consegue inspecionar o raciocínio: ele entendeu o problema? Se a análise no passo 2 estiver torta, você já sabe que o código do passo 3 também vai sair errado. Melhor corrigir ali, no raciocínio, do que perder tempo testando código quebrado depois.
Depurando Seu Par de IA: bugs comuns e como corrigir
Mesmo com bons prompts, LLMs erram. A chave é reconhecer os padrões de falha — os sinais clássicos de quando a IA derrapa — e ter um jeito claro de lidar com cada um.
Alucinações e como evitar
Alucinação é quando o modelo inventa algo com confiança absoluta. A melhor forma de reduzir isso é simples: coloque a informação verdadeira dentro do próprio prompt.
- Não peça assim: “Como eu uso a nova biblioteca de analytics da AcmeCorp para rastrear um evento ‘user_login’?”
- Peça assim: “Dada a documentação abaixo da biblioteca AcmeCorp, escreva um snippet Python que rastreia um evento ‘user_login’ com um parâmetro ‘user_id’.”
E aí você cola a documentação real.
O ponto é: você não está testando a memória do modelo. Está testando a capacidade dele de entender e sintetizar o que você forneceu. Isso tira o trabalho de “lembrar” da equação e reduz muito a chance de ele inventar método, endpoint ou parâmetro que não existe.
Fazendo Isso Virar Hábito
Se você usa LLM para tarefas repetitivas, não dá para tratar prompts como mensagens soltas. Eles passam a fazer parte do fluxo de engenharia e precisam ser cuidados como qualquer outro artefato técnico.
Versione seus prompts
Se um prompt gera seu client de API ou conduz uma refatoração seguindo o style guide da empresa, ele deixa de ser algo pontual. Ele passa a fazer parte do seu fluxo de engenharia. E deveria estar no Git junto com o código.
Por quê?
- Reprodutibilidade. Você sabe exatamente qual versão do prompt gerou aquele arquivo e consegue reproduzir o resultado quando precisar.
- Colaboração. Quando o prompt está no Git, o time pode revisar, ajustar e melhorar via pull request como qualquer outra parte da base.
- Histórico. Se uma nova versão de modelo quebrar um prompt que sempre funcionou, você tem um rastro claro para entender o que mudou.
Crie um ciclo de feedback
Teste prompts de forma sistemática. Se você encontrou um prompt que funciona para uma tarefa específica, salve ele.
Documente o que funciona e o que não funciona. Mantenha um doc simples ou um diretório com um “livro de receitas” de prompts que realmente entregam resultado. Isso evita muito retrabalho e poupa o time de reinventar a mesma coisa toda semana.
Defina o que é “bom”. Alinhe com o time como medir se um prompt está entregando: qualidade do código, menos idas e voltas, menos correções, menos ruído no PR. O que fizer sentido no seu fluxo.
Quando você trata prompts como parte do processo de engenharia, tudo fica mais previsível. Você sai do modo tentativa-e-erro e passa a ter um caminho claro até um resultado confiável.
Não tem truque. É só processo.
E à medida que os LLMs entram cada vez mais no dia a dia do time, esse processo deixa de ser “nice to have” e vira essencial.


