Introdução
Este post é para você que quer construir uma ferramenta interna de code review para o seu time e não sabe por onde começar. Ou se você só está curioso e quer entender como uma ferramenta dessas funciona nos bastidores. Vou abrir como a Kody, nossa agente open source de code review, funciona e explicar tudo o que fizemos para sair de 1% de taxa de implementação para 70%, processando milhões de linhas de código.
Faz sentido fazer Code Review com IA?
Ok, você já sabe que escrever código basicamente virou gerar código. E essa etapa ficou pelo menos 10x mais rápida. Claro, podemos questionar os riscos, a melhor forma de fazer isso, etc. Mas o fato é: a maioria dos times pelo menos dobrou a quantidade de código escrito ou gerado.
Isso é bom? Depende. Todo mundo sabe que linhas de código não significam mais produtividade. Ainda assim, existe potencial para aumentar a velocidade do time.
Então o que muda entre um time que transforma isso em produtividade real e um que não transforma? Vou usar duas métricas DORA aqui para tentar encontrar um número de referência e termos uma linha base de produtividade.
- Deploy Frequency: com que frequência estamos entregando em produção. Se isso aumenta, aumentamos pontos de contato com usuários e, como resultado, temos mais chances de encontrar PMF.
- Change Failure Rate: quantos defeitos e bugs estamos tendo em produção. Se aceleramos a velocidade de deploy mas o número de bugs cresce junto, claramente temos um problema.
Uma forma simples de combinar essas duas métricas é usar um “shipping score” que automaticamente te penaliza quando a taxa de falha sobe:
Shipping Score = Deploy Frequency × (1 − Change Failure Rate)
Exemplo rápido: se você faz 20 deploys/semana com 10% de taxa de falha, seu score é 20 × 0.9 = 18. Se você pula para 30 deploys/semana mas sua taxa de falha vai para 40%, seu score vira 30 × 0.6 = 18 também. Ou seja, você “andou mais rápido”, mas o valor líquido entregue é o mesmo, só que com mais risco e mais retrabalho.
Qualidade não é uma preocupação só por causa de IA. Na verdade, esse é um problema MUITO antigo. E vem sendo amplificado por vários motivos. Entre eles:
- Senioridade dos times: salários ficaram mais caros no pós-pandemia, times tiveram que fazer mais com menos. Muitos “sêniors de 2 anos” apareceram.
- Complexidade das aplicações: o que era um bom produto há 5 anos não é o mesmo hoje. A barra subiu.
- Escala das aplicações: temos muito mais usuários do que há alguns anos.
- Demanda de mercado: o mercado está mais exigente e ansioso, precisamos entregar o dobro em metade do tempo.
- Novas camadas de abstração (incluindo IA): camadas de aplicação continuam surgindo para simplificar ou aumentar a produtividade, incluindo IA. Isso geralmente traz alguns problemas junto também.
Então como as equipes normalmente resolviam problemas de qualidade?
- Code Review:
- Time de QA:
- Testes automatizados:
- Ferramentas de lint
- Ferramentas SAST, SAT
Essas ferramentas e cerimônias já não eram suficientes quando produzíamos metade do código, imagina agora que produzimos o dobro.
Então sim, por que não colocar IA para resolver esse problema também?

Muita gente fica desconfiada (com razão), porque usar LLMs para escrever código e usá-los para validar código soa como se tudo fosse “modo vibe”. E se a IA não é boa em escrever código, ela também não será boa em validar. Certo?
Sim e não. O LLM sozinho (agents, prompts etc.) realmente não é bom para dizer se algo tem qualidade ou não. Mas pense o seguinte: o LLM é só uma parte da ferramenta. Combinado com ASTs, o contexto certo e boas ferramentas de busca, ele pode ser uma ajuda muito boa para melhorar a qualidade do código.
É o mesmo motivo pelo qual grep pode ser inútil ou extremamente poderoso. Dar grep no repositório inteiro sem filtros é só barulho. Grep com o escopo certo, padrões certos e contexto vira uma ferramenta de verdade. LLMs são parecidos: o modelo importa, mas o pipeline importa mais.
O ponto é: construir uma IA para gerar código e outra para revisar código são coisas muito diferentes. Mesmo que o conceito de Agent exista nas duas, o segredo aqui é dar mais ferramentas (principalmente as determinísticas) para o Agent fazer um trabalho decente.
Se você só construir um wrapper em cima do LLM, seja um prompt simples ou um loop de agent, você vai frustrar o time com a qualidade. Confie em mim, essa foi a primeira versão da Kody em nov/2024 e os resultados foram bem ruins.
Hoje a Kody (nossa agente de code review) processa milhões de linhas de código. E conseguimos sair de 1% de implementação média para 70% fazendo isso. O objetivo deste post é te ensinar como.
Tipos de code review
Antes de pensar na arquitetura, vale separar uma coisa que muita gente mistura: code review no IDE e no Git não competem. Eles se complementam. A diferença é o timing e o nível de garantia que cada um entrega.
Code review na IDE (shift-left, feedback instantâneo)
Essa é a revisão que acontece enquanto você está codando. O objetivo aqui não é “validar tudo” e nem “bloquear merge”. É deixar o dev mais rápido e reduzir retrabalho, pegando problemas antes mesmo de existir um PR.
Onde isso entra no pipeline:
- Antes de abrir um PR: pré-checagens e sugestões rápidas.
- Durante o commit: validações simples, checklist, dicas de padrões do time.
O que faz sentido rodar no IDE:
- Nitpicks úteis (quando são baratos e muito óbvios): imports, naming, padrões repetidos, pequenos ajustes.
- Coisas contextuais ao arquivo atual: “essa função ficou grande demais”, “esse bloco pode ser simplificado”, “você esqueceu de tratar esse erro”.
- Sugestões que o dev pode aceitar na hora sem debate.
Ponto importante: no IDE é opcional e pessoal. Se você depender disso para garantir qualidade, vai se decepcionar. Algumas pessoas usam, outras ignoram.
Code review no Git (PR review, enforcement e rastreabilidade)
Essa é a revisão que acontece no lugar oficial: PR, CI e merge gate. O objetivo muda bastante: garantir consistência de processo, padrão do time e rastreabilidade. É onde você coloca o que precisa ser verdade antes de fazer o merge.
Onde isso entra no pipeline:
- Depois de abrir o PR: a revisão automatizada roda no diff, no contexto do repo e nas regras do time.
- Antes do merge: o que é crítico vira “blocker” ou pelo menos um “alerta sério”.
O que faz sentido rodar no Git:
- Coisas que exigem consenso do time: padrão de arquitetura, práticas de segurança, regras de negócio e “não pode passar”.
- Qualquer coisa que dependa do contexto do PR: interações entre arquivos, efeitos colaterais, mudanças de API, migrações, risco.
- Qualquer coisa que você queira medir e melhorar: aceitação, falsos positivos, “útil vs não útil”, tempo de resposta.
E é exatamente por isso que, quando você desenha a arquitetura, a pergunta certa não é “qual é melhor?”, mas: o que quero pegar cedo e barato (IDE) versus o que preciso garantir antes do merge (Git).
Desafios / Pontos de atenção
Ruído
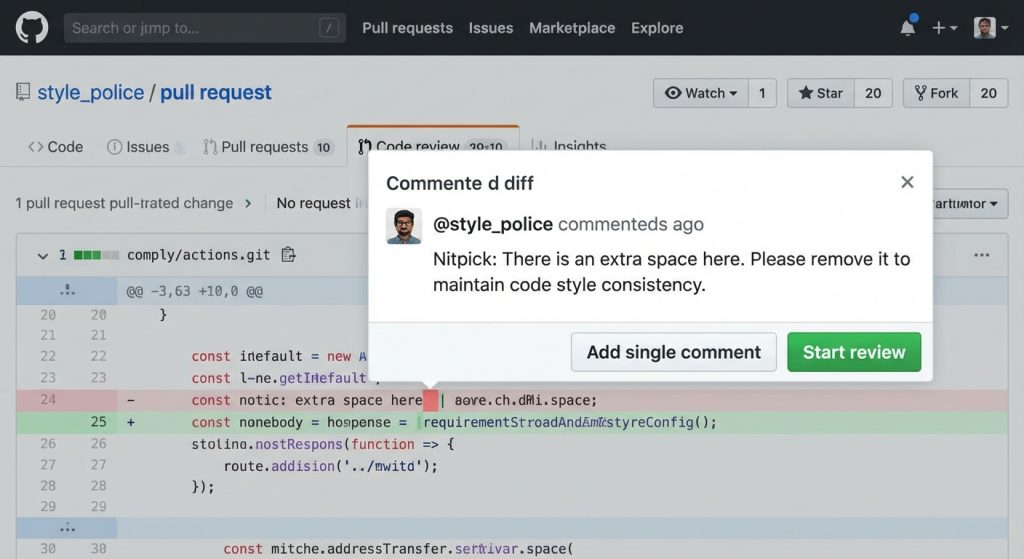
O maior inimigo de qualquer devtool, especialmente ferramentas que vivem no Git. Todo alarme que toca o tempo inteiro acaba sendo ignorado. Principalmente falsos positivos. Aqui o problema nem é alucinação ou grandes erros do LLM. O problema são comentários nitpick, do tipo que tecnicamente fazem sentido dependendo do momento do time, objetivos, contexto etc. Nosso objetivo é reduzir esse tipo de comentário o máximo possível.
Custo
Esse problema é tão grande quanto qualquer problema de custo de empresa. Se orçamento é um problema para você, preste atenção nas técnicas que vou compartilhar aqui, porque para chegar a um bom resultado de revisão, muita coisa é gerada e descartada. Então naturalmente isso pode virar um problema se usamos um modelo com input e output caros.
Segurança / privacidade
Estamos lidando com um dos maiores ativos de uma empresa: seu código-fonte. Precisamos ter muito cuidado com quais permissões damos por agente, como isolamos contexto e como tratamos informações. Os maiores problemas podem ser: agente com permissões demais, integrações com MCPs, falta de isolamento de ambiente. /// pensar em mais casos aqui.
Rate limits da API do Git
Todas as ferramentas Git como GitHub, Bitbucket, Azure DevOps e GitLab têm limites de rate bem modestos. Precisamos ter cuidado ao postar e buscar informações para não travar processos por causa dessas limitações.
Para não ficar longo demais, vou parar por aqui. Na próxima parte vamos falar sobre a arquitetura geral e cada peça dela.


