Como escalar DevOps em grandes empresas

A conversa sobre como escalar DevOps em uma empresa grande sempre fica travada em ferramentas. A gente discute Jenkins versus GitLab, Terraform versus Pulumi, ou qual plataforma de observabilidade padronizar. Esses são os argumentos errados. Em grandes empresas, DevOps não para porque você escolheu a ferramenta de CI/CD errada. Ele para por causa da estrutura organizacional, dos modelos de financiamento e dos hábitos culturais que automação nenhuma resolve. Entender as nuances de DevOps e Platform Engineer ajuda a jogar um luz nesses pontos.
Startups fazem DevOps de forma natural. Elas não têm escolha. Um time de cinco pessoas não tem um departamento separado de operações nem um change advisory board. A responsabilidade é total, e os ciclos de feedback são imediatos. Empresas grandes são um conjunto de decisões legadas, dívida técnica acumulada e fluxos de comunicação moldados por anos de Lei de Conway.
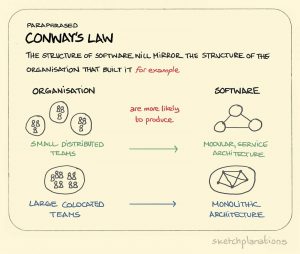
Jogar uma ferramenta nova nesse ambiente não muda o sistema por baixo. Só automatiza uma etapa de um processo que já está quebrado.
Não estou aqui para defender DevOps. Quero analisar por que seus princípios tantas vezes não sobrevivem ao contato com a realidade corporativa e olhar para as mudanças estruturais que de fato funcionam.
Os limites das melhorias locais de DevOps
O que muitas vezes passa por “transformação DevOps” é só uma sequência de otimizações locais. Um único time automatiza sua suíte de testes ou cria um script de deploy. Vê um ganho de velocidade, declara sucesso e a iniciativa perde a força depois. O resto da organização não vê benefício algum porque os gargalos reais continuam intactos.
Quando a automação isolada cria novos silos
Imagine um time de desenvolvimento que constrói um pipeline de CI/CD totalmente automatizado para o seu serviço. É uma obra de arte, fazendo deploy em produção em minutos. Mas ninguém fora do time sabe como aquilo funciona. O time central de operações não consegue dar suporte, o time de segurança não consegue auditar, e nenhum outro time de desenvolvimento consegue reutilizar.
Você não removeu um silo. Só trocou um silo manual, bem compreendido, por outro automatizado, veloz e opaco. Quando algo quebra às 2 da manhã, o engenheiro de plantão em operações não faz ideia de como depurar essa criação sob medida. O time original vira um ponto único de falha. Escalar esse modelo para 100 times significa ter 100 pipelines de deploy diferentes e impossíveis de sustentar, aumentando a fragilidade do sistema e a carga cognitiva de todo mundo.
O custo de um time central de “DevOps”
O próximo erro comum é criar um “Time de DevOps”. Na superfície, parece lógico, você contrata especialistas para cuidar da automação. Na prática, esse novo time quase sempre vira mais um silo, o “pessoal da automação” que fica entre dev e ops.
Times de desenvolvimento abrem tickets para o time de DevOps configurar um pipeline. O time de operações abre tickets para configurar monitoramento. Em vez de deixar desenvolvedores serem donos do código ao longo de todo o ciclo de vida, você colocou um novo intermediário. Esse time central rapidamente vira um gargalo, sobrecarregado de demandas e distante do dia a dia dos times de produto. Eles não estão fazendo DevOps. Estão só fazendo ops com scripts melhores. As passagens de bastão e a responsabilidade dividida que o DevOps queria resolver continuam firmes e fortes.
Proliferação de ferramentas e práticas inconsistentes
Sem uma estratégia clara, os times adotam ferramentas por preferência pessoal ou pelo que estava em alta no Hacker News naquela semana. Um time usa Jenkins, outro CircleCI, e um terceiro monta algo customizado com scripts em shell. Essa dispersão torna impossível estabelecer gates consistentes de segurança ou qualidade.
Cada ferramenta tem seu próprio ecossistema de plugins, seu próprio modelo de IAM e sua própria forma de armazenar segredos. Um time central de segurança não tem como aplicar padrões em dezenas de toolchains diferentes. O resultado é um risco de segurança constante e de baixo nível, além da incapacidade de responder perguntas básicas de governança como: “Qual versão do Log4j está rodando em produção agora?”
Mudando o foco: DevOps como habilidade organizacional
O objetivo é parar de tratar DevOps como um time que você contrata ou uma ferramenta que você compra. É uma capacidade organizacional, como planejamento financeiro ou gestão de produto. O trabalho real é mudar como os times são estruturados, financiados e medidos, o que é muito mais difícil do que escrever YAML.
Descentralizar a propriedade, não a responsabilidade
DevOps bem feito em escala empurra a propriedade para as pontas, para os times de produto que constroem os serviços. Eles são donos do código do commit até a produção e além. É o modelo “you build it, you run it”.
Isso não significa que cada time está por conta própria. A organização continua responsável por oferecer uma plataforma segura, confiável e fácil de usar. A ideia é dar autonomia para os times se moverem rápido dentro de limites bem definidos, não largá-los para resolver tudo do zero.
Bloqueios comuns ao escalar DevOps
A mudança para um modelo descentralizado encontra barreiras previsíveis dentro de uma empresa grande.
Resistência de departamentos tradicionais
Grupos como infraestrutura, segurança e compliance costumam ser construídos em torno de gates de controle e revisões manuais. Todo o modelo operacional pode estar baseado em impedir que desenvolvedores acessem diretamente sistemas de produção. Um modelo self-service pode soar como perda de controle e relevância.
Falta de objetivos compartilhados
Se times de desenvolvimento são medidos por velocidade de entrega de features e times de operações são medidos por uptime, eles estão em conflito direto. Um desenvolvedor que publica uma mudança que pode arriscar a estabilidade está fazendo seu trabalho, e uma pessoa de ops que resiste a essa mudança também está fazendo o dela. Sem objetivos compartilhados, como lead time para mudanças ou mean time to recovery (MTTR), os times continuam otimizando seus KPIs locais às custas do sistema como um todo.
Medo de perder controle.
É uma preocupação válida, especialmente em indústrias reguladas. A ideia de centenas de desenvolvedores podendo fazer deploy em produção é assustadora para um CISO cuja função depende de manter conformidade. Esse medo só pode ser enfrentado com sistemas que ofereçam guardrails automatizados e inegociáveis, não mantendo etapas manuais de revisão.
Como fazer isso funcionar de verdade
Isso exige um redesenho deliberado dos sistemas técnicos e organizacionais com os quais desenvolvedores interagem todos os dias.
Tratar times de plataforma como provedores internos de produto
O melhor padrão para habilitar autonomia de desenvolvedores é a internal developer platform (IDP), gerenciada por um Time de Platform Engineering. O ponto-chave é tratar essa plataforma como um produto interno.
Serviços de plataforma são produtos para desenvolvedores internos.
Os clientes do time de plataforma são os próprios desenvolvedores da empresa. O trabalho deles é construir e manter ferramentas, serviços e infraestrutura que facilitem para os times de produto entregar valor. Isso inclui pipelines de CI/CD, stacks de observabilidade, ambientes de teste e infraestrutura gerenciada.
Foco em experiência do desenvolvedor e self-service.
O sucesso da plataforma é definido pela experiência do desenvolvedor. É mais fácil para um time usar a oferta gerenciada de PostgreSQL da plataforma ou criar a própria solução? Se o caminho oficial está cheio de fricção, tickets e longas esperas, desenvolvedores vão contornar. A plataforma precisa ser self-service, orientada por API e bem documentada.
Medir o time de plataforma por adoção.
Não meça o time de plataforma por uptime ou quantidade de tickets fechados. Meça se as pessoas estão usando o que eles constroem. Times de desenvolvimento estão usando voluntariamente os serviços da plataforma? Conseguem entregar mais rápido por causa disso? Se os times vivem criando suas próprias soluções, é um sinal de que a plataforma não atende às necessidades. Forçar adoção por imposição é sinal de fracasso da plataforma, não de sucesso.
Padronizar pipelines para escalar seus esforços
Não dá para ter cada time construindo um pipeline sob medida. Padronização é necessária, mas deve habilitar velocidade, não restringir.
Estabeleça “golden paths” com templates configuráveis.
Um golden path é um caminho suportado e bem documentado para construir, testar e fazer deploy de um tipo específico de aplicação, como um serviço Java Spring Boot ou um container em Python. O time de plataforma fornece um template de pipeline que cobre 80% das necessidades comuns.
Exija gates de segurança e compliance.
Esses templates devem ter etapas obrigatórias e embutidas de análise estática (SAST), software composition analysis (SCA) e outros checks de conformidade. Ao incorporar isso no golden path, segurança vira parte automatizada do processo, não um gate manual no final.
Permita extensões específicas de cada time.
O golden path não deve ser uma camisa de força. Times precisam poder adicionar etapas ou testes específicos ao pipeline. O núcleo é padronizado, mas as bordas são flexíveis. Isso acomoda necessidades especializadas sem abrir mão da governança central.
Decidir como escolher ferramentas sem criar caos
Em vez de um comitê central de arquitetura ditando cada ferramenta, um modelo federado oferece melhor equilíbrio.
Tome decisões centrais para ferramentas críticas.
Escolhas sobre tecnologias fundamentais que afetam a organização inteira, como o provedor de nuvem, o orquestrador de containers ou o sistema de identidade, devem ser feitas de forma centralizada. São decisões de alto impacto e baixa reversibilidade.
Deixe comunidades escolherem ferramentas específicas de time.
Para ferramentas usadas dentro do domínio de um time, como uma biblioteca específica de testes ou IDE, deixe que escolham o que funciona melhor. Crie comunidades de prática onde engenheiros compartilhem conhecimento e estabeleçam boas práticas de forma voluntária.
Tenha caminhos claros de descontinuação para sistemas antigos.
Governança também significa aposentar sistemas antigos ativamente. Quando uma nova ferramenta ou plataforma é introduzida, precisa existir um plano claro e financiado para migrar do sistema antigo. Sem isso, você só aumenta a dispersão.
Construir uma cultura de transparência e aprendizado
Por fim, são as mudanças culturais e de processo que fazem as mudanças técnicas se sustentarem, contribuindo para construir uma cultura de engenharia forte.
Realize post-mortems sem culpa entre departamentos.
Quando um incidente acontece, o objetivo é entender as causas sistêmicas, não encontrar um culpado. Um bom post-mortem envolve pessoas de todos os times envolvidos (dev, ops, segurança, produto) para ter uma visão completa da falha. Isso constrói confiança e revela problemas escondidos no sistema.
Compartilhe conhecimento por meio de conferências internas e demos.
Crie espaços onde times possam mostrar o que construíram. Quando um time resolve um problema difícil, ele deve ser reconhecido por compartilhar a solução com os demais. Isso evita trabalho paralelo e ajuda boas ideias a se espalharem de forma orgânica.
Use métricas que recompensem resultados compartilhados.
Afaste-se de KPIs isolados. Meça times com base em métricas de engenharia compartilhadas, como lead time para mudanças, frequência de deploy, MTTR e taxa de falha em mudanças. Isso força colaboração, porque nenhum time sozinho consegue melhorar esses números. Isso também precisa aparecer no modelo de financiamento. Sair de financiamento por projeto (constrói uma feature, desmonta o time) para financiamento por produto (um time durável é dono de um serviço) é essencial para criar responsabilidade de longo prazo.