Small pull requests are a risk control, p95 shows why
People talk about pull request size like it’s a style preference. I used to think the same, until I put cycle time next to PR size and looked at them together.
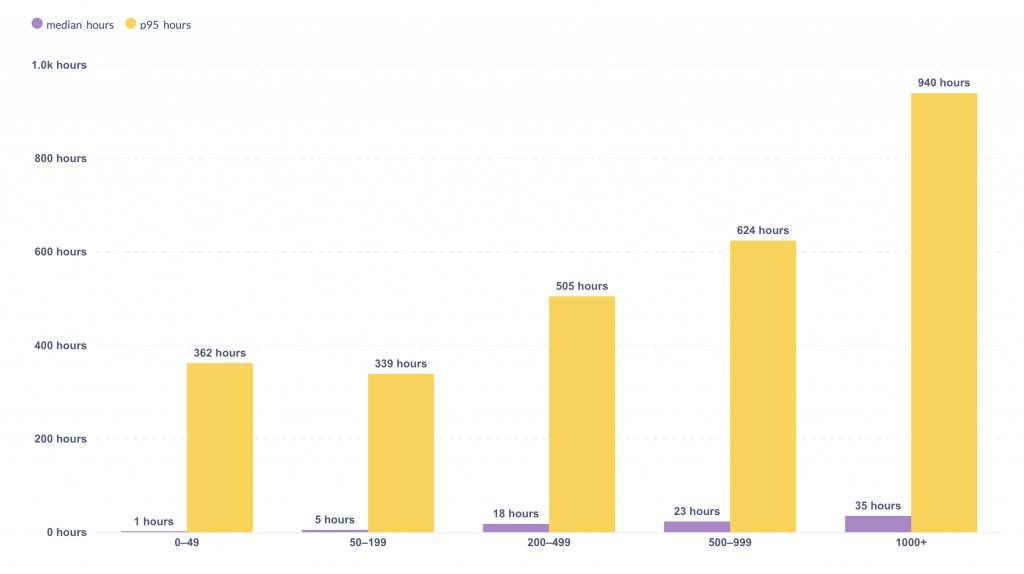
We grouped 91,444 pull requests by total number of changes and measured how long they stayed open, from open to close. Then we looked at two cuts:
- – the median (what a typical PR looks like)
- – p95 (how long the slowest 5% take)
That p95 line is the part I keep thinking about.
How we measured it
Buckets are based on `totalChanges`:
- 0–49
- 50–199
- 200–499
- 500–999
- 1000+
Cycle time is measured in hours between opened and closed timestamps. For each bucket we calculated median and p95.
The numbers
| PR size | median (hours) | p95 (hours) |
| 0-49 | 1 | 362 |
| 50-199 | 5 | 339 |
| 200-499 | 18 | 505 |
| 500-999 | 23 | 624 |
| 1000+ | 940 | 940 |
Two things jump out.
First, the median goes up as PRs get bigger. That part is expected. A 1000+ change PR takes longer to close than a 20 change PR.
Second, and this is the one that changes how I think about the problem, p95 turns into weeks once you pass 200+ changes. By the time you are in 1000+, the slow end of the distribution is sitting at about 39 days.
If you lead a team, that long tail is where planning goes to die.
The part that surprised me
The 0–49 bucket still has a p95 of about 15 days.
A PR that small taking two weeks is rarely a “hard code” problem. It usually feels like the social and operational stuff:
- the PR landed in a review queue no one owns
- the author moved on and context disappeared
- there is a dependency, or the work got de-prioritized
- the PR is waiting on someone who is not around, or not on the hook
Small PRs can still rot. When they do, the fix is often boring, and that is good news because boring fixes are easy to try.
Why bigger PRs get stuck
I do not think there is a single cause. Bigger PRs tend to bring more of everything:
- more surface area to review, so reviewers postpone it
- more people involved, so handoffs multiply
- more time open, so rebases and conflicts show up more often
- more risk, so the PR gets treated like a mini project
All of that pushes work into the part of the distribution where p95 lives.
What I would do if this was my team
I would treat PR size as a risk knob, not a productivity hack.
1. Pick a default target that matches how your team works
For many teams, keeping most PRs under 200 changes is a good starting point. It keeps the tail from getting too weird.
2. Add a separate path for large PRs
If a PR needs to be big, I want it to be big on purpose. Split refactors from behavior changes, use feature flags, stack smaller PRs, write a short note up front that explains intent and boundaries.
3. Put a clock on “small PRs stuck for days”
If a 30 change PR is open for a week, it should show up somewhere visible. I would rather close it and reopen later than let it sit half dead.
4. Make review ownership explicit
Queues rot when no one owns them. One person owning triage for the week can do more than any new template.
None of this requires new tools. It is mostly policy and habit.
What I still want to check
Two follow ups would make this cleaner:
- merged vs not merged, since abandoned PRs can inflate the tail
- breakdown by status, since “closed” can hide a lot of different outcomes
Even without those cuts, the shape is hard to ignore. Median moves with PR size, and p95 gets ugly once PRs get large.