How to scale DevOps in large enterprises

The conversation about how to scale DevOps in a large company always gets stuck on tools. We argue about Jenkins versus GitLab, Terraform versus Pulumi, or which observability platform to standardize on. These are the wrong arguments. In large enterprises, DevOps doesn’t stall because you picked the wrong CI/CD tool. It stalls because of the organizational structure, funding models, and cultural habits that no amount of automation can fix. Understanding the nuances of DevOps and Platform Engineering helps shed light on these issues.
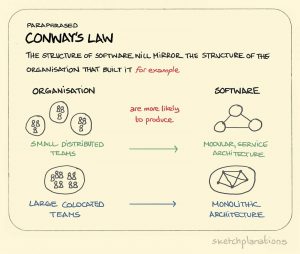
Startups do DevOps naturally. They don’t have a choice. A five-person team doesn’t have a separate operations department or a change advisory board. Ownership is total, and feedback cycles are immediate. Large companies are a collection of legacy decisions, accumulated technical debt, and communication flows shaped by years of Conway’s Law.
Throwing a new tool into that environment doesn’t change the underlying system. It just automates one step of a process that is already broken.
I’m not here to defend DevOps. I want to examine why its principles so often fail to survive contact with corporate reality and look at the structural changes that actually work.
The limits of local DevOps improvements
What often passes for “DevOps transformation” is just a sequence of local optimizations. A single team automates its test suite or creates a deployment script. They see a speed boost, declare victory, and the initiative loses momentum shortly after. The rest of the organization sees no benefit because the real bottlenecks remain untouched.
When isolated automation creates new silos
Imagine a development team that builds a fully automated CI/CD pipeline for its service. It’s a masterpiece, deploying to production in minutes. But no one outside the team knows how it works. The central operations team can’t support it, the security team can’t audit it, and no other development team can reuse it.
You didn’t remove a silo. You just replaced a well-understood manual silo with an automated, fast, and opaque one. When something breaks at 2 a.m., the on-call operations engineer has no idea how to debug this custom creation. The original team becomes a single point of failure. Scaling this model to 100 teams means having 100 different deployment pipelines that are impossible to sustain, increasing system fragility and everyone’s cognitive load.
The cost of a central “DevOps” team
The next common mistake is creating a “DevOps Team.” On the surface, it sounds logical: hire specialists to handle automation. In practice, this new team almost always becomes another silo, the “automation people” sitting between dev and ops.
Development teams open tickets for the DevOps team to configure a pipeline. The operations team opens tickets to set up monitoring. Instead of letting developers own their code throughout its entire lifecycle, you’ve introduced a new middle layer. This central team quickly becomes a bottleneck, overloaded with requests and disconnected from the daily reality of product teams. They’re not doing DevOps. They’re just doing ops with better scripts. The handoffs and split ownership that DevOps aimed to eliminate remain fully intact.
Tool sprawl and inconsistent practices
Without a clear strategy, teams adopt tools based on personal preference or whatever was trending on Hacker News that week. One team uses Jenkins, another uses CircleCI, and a third builds something custom with shell scripts. This fragmentation makes it impossible to establish consistent security or quality gates.
Each tool has its own plugin ecosystem, its own IAM model, and its own way of storing secrets. A central security team cannot enforce standards across dozens of different toolchains. The result is a constant, low-level security risk and an inability to answer basic governance questions like: “Which version of Log4j is running in production right now?”
Shifting the focus: DevOps as an organizational capability
The goal is to stop treating DevOps as a team you hire or a tool you buy. It’s an organizational capability, like financial planning or product management. The real work is changing how teams are structured, funded, and measured, which is much harder than writing YAML.
Decentralize ownership, not responsibility
DevOps done well at scale pushes ownership to the edges, to the product teams building the services. They own the code from commit to production and beyond. It’s the “you build it, you run it” model.
This doesn’t mean each team is on its own. The organization is still responsible for providing a secure, reliable, and easy-to-use platform. The idea is to give teams autonomy to move fast within well-defined boundaries, not to leave them to figure everything out from scratch.
Common blockers when scaling DevOps
Moving to a decentralized model runs into predictable barriers inside a large company.
Resistance from traditional departments
Groups like infrastructure, security, and compliance are often built around control gates and manual reviews. The entire operating model may be based on preventing developers from directly accessing production systems. A self-service model can feel like a loss of control and relevance.
Lack of shared objectives
If development teams are measured by feature delivery speed and operations teams are measured by uptime, they are in direct conflict. A developer who ships a change that risks stability is doing their job, and an ops person who resists that change is also doing theirs. Without shared objectives like lead time for changes or mean time to recovery (MTTR), teams will keep optimizing their local KPIs at the expense of the overall system.
Fear of losing control.
It’s a valid concern, especially in regulated industries. The idea of hundreds of developers being able to deploy to production is terrifying for a CISO whose role depends on maintaining compliance. That fear can only be addressed with systems that provide automated, non-negotiable guardrails, not by keeping manual review steps in place.
How to make this actually work
This requires a deliberate redesign of the technical and organizational systems developers interact with every day.
Treat platform teams as internal product providers
The best pattern to enable developer autonomy is an internal developer platform (IDP), managed by a Platform Engineering Team. The key point is to treat that platform as an internal product.
Platform services are products for internal developers.
The customers of the platform team are the company’s own developers. Their job is to build and maintain tools, services, and infrastructure that make it easier for product teams to deliver value. This includes CI/CD pipelines, observability stacks, testing environments, and managed infrastructure.
Focus on developer experience and self-service.
The platform’s success is defined by developer experience. Is it easier for a team to use the platform’s managed PostgreSQL offering or to spin up their own solution? If the official path is full of friction, tickets, and long wait times, developers will route around it. The platform needs to be self-service, API-driven, and well documented.
Measure the platform team by adoption.
Don’t measure the platform team by uptime or number of tickets closed. Measure whether people are actually using what they build. Are development teams voluntarily using platform services? Are they shipping faster because of them? If teams keep building their own solutions, it’s a sign the platform isn’t meeting their needs. Forcing adoption through mandates is a sign of platform failure, not success.
Standardize pipelines to scale your efforts
You can’t have every team building a custom pipeline. Standardization is necessary, but it should enable speed, not restrict it.
Establish “golden paths” with configurable templates.
A golden path is a supported and well-documented way to build, test, and deploy a specific type of application, such as a Java Spring Boot service or a Python container. The platform team provides a pipeline template that covers 80% of common needs.
Require security and compliance gates.
These templates should include mandatory, built-in steps for static analysis (SAST), software composition analysis (SCA), and other compliance checks. By embedding this into the golden path, security becomes an automated part of the process, not a manual gate at the end.
Allow team-specific extensions.
The golden path shouldn’t be a straitjacket. Teams need to be able to add specific steps or tests to their pipeline. The core is standardized, but the edges are flexible. This accommodates specialized needs without giving up central governance.
Deciding how to choose tools without creating chaos
Instead of a central architecture committee dictating every tool, a federated model offers a better balance.
Make central decisions for critical tools.
Choices about foundational technologies that affect the entire organization, such as the cloud provider, container orchestrator, or identity system, should be made centrally. These are high-impact, low-reversibility decisions.
Let communities choose team-specific tools.
For tools used within a team’s domain, such as a specific testing library or IDE, let them choose what works best. Create communities of practice where engineers share knowledge and establish best practices voluntarily.
Have clear deprecation paths for legacy systems.
Governance also means actively retiring old systems. When a new tool or platform is introduced, there needs to be a clear, funded plan to migrate away from the old system. Without that, you just increase fragmentation.
Building a culture of transparency and learning
Finally, it’s the cultural and process changes that make technical changes stick, contributing to building a strong engineering culture.
Run blameless post-mortems across departments.
When an incident happens, the goal is to understand systemic causes, not to find someone to blame. A good post-mortem involves people from all teams involved (dev, ops, security, product) to get a complete view of the failure. This builds trust and surfaces hidden problems in the system.
Share knowledge through internal conferences and demos.
Create spaces where teams can showcase what they’ve built. When a team solves a hard problem, they should be recognized for sharing that solution with others. This avoids duplicated effort and helps good ideas spread organically.
Use metrics that reward shared outcomes.
Move away from isolated KPIs. Measure teams based on shared engineering metrics such as lead time for changes, deployment frequency, MTTR, and change failure rate. This forces collaboration, because no single team can improve those numbers alone. This also needs to show up in the funding model. Moving from project-based funding (build a feature, disband the team) to product-based funding (a durable team owns a service) is essential to create long-term accountability.