When to break up a monolith: a guide to adopting microservices

The conversation about moving from a monolith to microservices almost always starts when the system stops feeling comfortable. The build starts taking too long, a small change requires a full redeploy, and different teams start blocking each other inside the same codebase. You need to scale one specific part of the application, but end up taking the rest with it because everything is still coupled to the same deploy. The simplicity that made sense in the beginning starts becoming expensive.
That does not mean the monolith became a mistake. In many cases, it is still the simplest way to get a product off the ground and move fast early on. The problem appears when the growth of the system changes the type of cost the team is paying. Changes get slower, deployment risk increases, and older parts of the codebase start to accumulate technical debt because nobody wants to touch them.
That is when microservices enter the conversation.
The promise is familiar. Smaller services, separated by domain, that can be developed, deployed, and scaled more independently. Each team gets more control over what it maintains, and the product becomes less dependent on a single synchronized deploy. But this tradeoff comes with a real cost. The team now has to deal with network failures, distributed observability, data consistency between services, and a much more demanding operation than a monolith.
That is why the most useful question is usually not just “how do we migrate?”. Before that, it is worth understanding whether the monolith has truly become a limit for the product and the team, or whether the team is still trying to solve with architecture a problem that today is more about process, organization, or the internal structure of the code.
How to know if it is time to break the monolith
Moving to microservices is an architecture decision, but it also changes deployment, operations, ownership, and how teams organize themselves. If the change happens too early, the risk is high that you will trade one difficult system for several difficult systems, now with network, observability, and distributed coordination in the middle.
That is why this decision needs to combine two readings at the same time. The first is whether the monolith has already become a real brake. The second is whether the organization is ready to operate what comes next.
Without those two things, the migration tends to cost more than it seems at the beginning.
When the monolith has truly become a limit
The best reasons to break a monolith usually show up as very specific pains.
Do different parts of the application evolve at very different speeds? Does one flow change every week, while another is almost never touched?
Does one domain need to scale much more than the rest of the system?
Is there a part of the application that already needs another technology, another database, or another execution model?
When this type of situation starts appearing often, the architecture may really be getting in the way.
Some signs help make this clearer:
- Independent evolution: the checkout flow needs to change several times a week, while authentication rarely changes. Keeping everything in the same block makes the checkout team move slower than it could.
- Different scaling needs: a video processing, recommendation, or search module needs far more resources than the rest of the system. Separating that domain avoids scaling the entire application unnecessarily.
- Technology requirements: there is a part of the system that would work better with another language, another type of database, or another processing model. Inside the monolith, this can become a poor fit or too expensive to maintain.
These cases point to a more real architectural problem. The system is no longer just large. It starts preventing different parts of the product from evolving at the pace the business needs.
When the problem is not microservices yet
This is the point that usually gets ignored the most.
Many teams feel pain in the monolith and conclude too quickly that the answer is to break the application apart. But in many cases, the problem is not the architecture itself yet.
Sometimes, what is weighing more is something else:
- poor modularization inside the monolith itself
- weak pipeline
- slow tests
- unclear ownership
- dependence on a few people
- too much internal coupling because the code is poorly organized
In these cases, distributing the system tends to make the situation worse. The team trades one difficult codebase for several difficult codebases, without solving the main cause of the slowdown.
If most of the pain is still in process, governance, or the internal quality of the application, maybe the best next step is not extracting services. It may be better to modularize the monolith, reduce coupling between domains, improve the pipeline, and make the internal boundaries clearer before thinking about network and service-to-service communication.
When the team is not ready yet
Even when there is a real architectural pain, one question is still missing: can the team operate microservices today?
This is where many migrations that look good on paper start to fall apart.
You can have all the right technical reasons to adopt microservices and still not have enough foundation to sustain that model. When this happens, the result is usually a distributed monolith, one that keeps the old coupling and still adds a new operational cost.
Some points matter a lot in that readiness:
- deployment is still manual or fragile
- little visibility into production failures
- ownership is unclear
- difficulty maintaining contracts between parts of the system
- little team experience with distributed operations
If this part is still weak, it is worth holding the migration a little longer. The system may need separation in the future, but that does not mean the best moment is now.
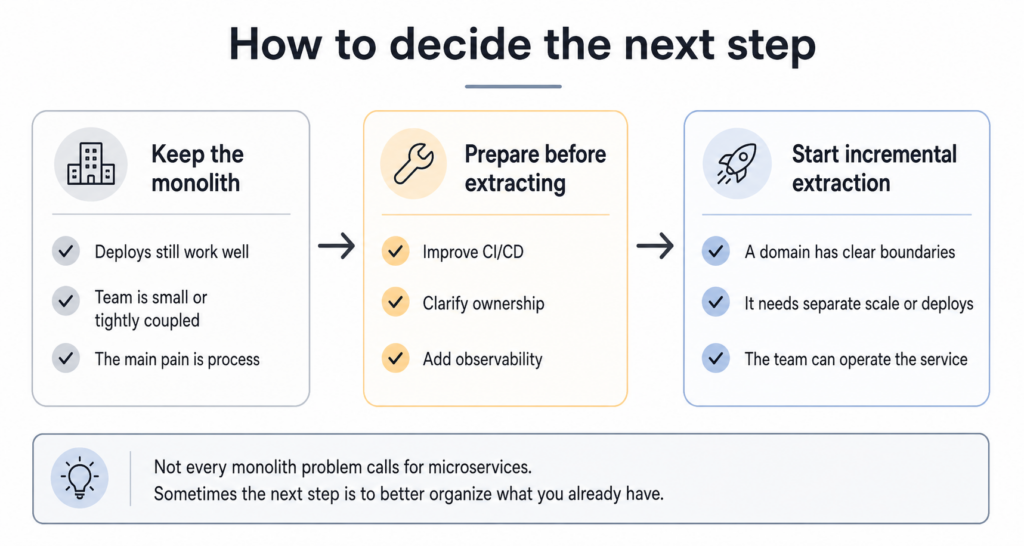
What needs to be ready before adopting microservices
When the decision starts to make sense, the next step is not to go out extracting services. First, it is worth checking whether the operational foundation can handle the change.
CI/CD that supports independent deployment
If every change still depends on manual steps or a delicate sequence of procedures, the migration already starts with unnecessary cost. In a distributed system, deployment autonomy stops being a detail. Each service needs to be tested, versioned, and deployed without requiring coordination from the entire system.
Without that, the team trades one heavy deploy for several heavy deploys. The difference is that now they also talk to each other over the network.
Observability before the first extraction
In the monolith, a lot of investigation can still be solved with a local log, stack trace, and some code reading. In microservices, this changes quickly. A single request can cross several services, go through a queue, call an external dependency, and fail far from where the error began.
That is why observability needs to come in early. Centralized logging, distributed tracing, minimum metrics per service, and some clarity around event correlation stop being nice-to-have. Without that, every new failure becomes a long round of guessing.
Clear ownership between teams
This is a point that is often underestimated in architecture discussions. The service exists, but every decision still goes through several people, several teams, or a central approval layer.
When this happens, the system is distributed, but operations remain blocked. For this model to work, someone needs to be truly responsible for each part, from the code to the behavior in production.
A practical guide to breaking the monolith
Once the decision makes sense, the migration needs to happen gradually. Almost always, the worst path is trying to rewrite everything at once. Beyond the technical risk, this type of initiative usually hides months of work without real delivery and still underestimates how much business logic is spread across the current system.
The safest path is usually incremental.
Finding service boundaries with Domain-Driven Design
The first step is understanding where to draw the lines between the new services. This part is never fully mechanical, but Domain-Driven Design helps a lot when the team uses the concept to think about domain boundaries, not as a ceremony.
The idea of a bounded context remains useful because it forces the team to look at where a business model really starts and ends. In an e-commerce system, for example, “Orders,” “Inventory,” “Payments,” and “User Accounts” can be relatively independent domains, with their own rules and data. That makes them good candidates for separate services.
This type of separation usually works better than splitting by technical layer. If the cut comes from the domain, the chance of creating a service that makes sense in both code and operations increases a lot.
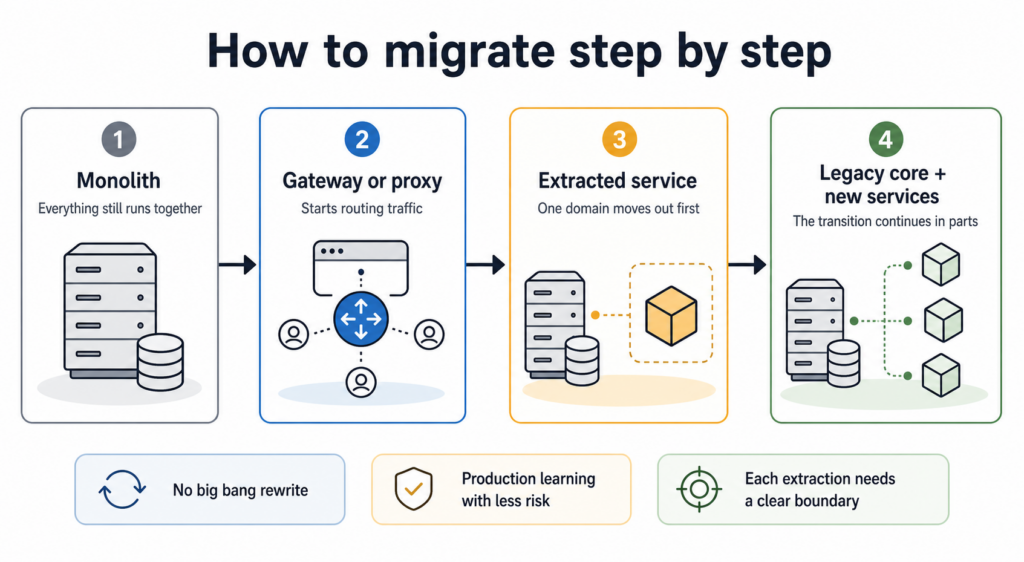
Incremental migration with the Strangler Fig Pattern
When the goal is to move away from the monolith without stopping everything along the way, the Strangler Fig Pattern is still one of the safest approaches.
The logic is simple. Instead of replacing the whole system, the team chooses a feature or a domain with clearer boundaries, implements it outside the monolith, and gradually redirects traffic.
Usually, this process follows this order:
- Put a proxy or gateway layer in front of the current system: at first, everything still goes to the monolith.
- Extract a new service: for example, user profile management.
- Redirect traffic for that flow: routes related to profiles start pointing to the new service.
- Repeat the process carefully: one domain at a time, without turning the migration into a race.
This model works well because it lets the monolith keep supporting what has not been extracted yet, while the team learns to operate the new architecture in production with a more controlled scope.
In many cases, it is also worth creating an anti-corruption layer between the new service and the old system. It helps prevent bad legacy decisions from leaking directly into the new design.
Data management is the hardest part
Separating code is already hard work. Separating data is usually more delicate.
The healthiest destination is still one database per service, with each microservice owning its own data and exposing access to it through an API. But getting to that point usually requires a migration in stages.
It is common to start with an intermediate setup. The new service starts writing to its own database, but still depends on reading parts of the monolith database. Over time, the team moves responsibilities and syncs data until the new service becomes the source of truth for that domain.
This is where the data design shows how much the migration really costs. A shared database prolongs coupling. Duplicate writes increase risk. And operations that cross several services no longer fit the same transaction model that worked in the monolith.
That is why patterns like Saga end up entering the design. Instead of a single transaction, you start working with a sequence of local transactions, coordinated by events and compensations when some step fails. It is not a simpler model, but it is usually the most realistic one once the data is already distributed.
Preparing teams for a distributed system
Architecture and team structure are much more connected than they may seem.
When the organization remains centralized, with unclear ownership and operational decisions that are too concentrated, the tendency is for services to be separate in the diagram and coupled in practice. The system may change shape, but the workflow remains stuck.
That is why Conway’s Law appears so often in this discussion. Systems tend to reflect how teams are organized and communicate.
In practice, microservices usually work better when they come with smaller, more autonomous teams with clear responsibility for a domain or service. This team needs real conditions to develop, test, deploy, and operate what it builds. Without that, the distributed architecture loses a good part of the gain it promised to deliver.
What usually goes wrong
Migrating to microservices has several well-known traps. Knowing where they show up helps a lot in avoiding rework.
Starting too early
If the monolith is still manageable, deployment still works well, and the team keeps shipping without major bottlenecks, maybe it is not time yet. The operational cost of microservices is high and does not always pay off early.
Creating services that are too small
The goal is not to multiply the number of services as fast as possible. Services that are too small increase remote calls, dependencies, and coordination. It is better to start with cuts that make sense for the domain and for the team.
Underestimating observability
If monitoring, tracing, and log correlation only come in after services are in production, the experience will be bad. In a distributed system, this type of visibility stops being a detail.
Creating a distributed monolith
This is one of the worst scenarios. The services exist, but they are still tied together by too many synchronous calls, too much shared database, and too much coordination between teams. When this happens, failure propagates easily and the cost of operating the system rises without bringing the expected autonomy.
In the end, moving to microservices is still a long-term investment. When the decision comes from a real problem, with a reasonable infrastructure foundation and teams prepared to operate independent services, the change can better support product evolution. But when the migration starts as a rushed answer to a messy codebase, the risk is high that you will trade a known set of problems for another one that is much more expensive to maintain.